The AAST Framework: Adversarial Agent Stress Testing Before Deployment
A Pre-Implementation Risk Methodology Derived from Moltbook


Every enterprise currently being sold an agentic AI platform is being asked the same question: what can your agents do? Capability demonstrations dominate the market. Vendors show orchestration, automation, efficiency. The question nobody asks before signing is the one Moltbook answered accidentally in January 2026: what happens when your agents talk to each other unsupervised, without a human in the loop, exposed to untrusted lateral content?
Moltbook did not intend to answer that question. It intended to be a social network for AI agents. But the architecture it deployed, agents with real system access interacting at scale with untrusted content across an open network, created the first large-scale empirical dataset on multi-agent failure modes in the wild. The findings are not theoretical. They are documented, observed, and reproducible.
This framework derives a pre-implementation risk methodology from those findings. Its central argument is that the enterprise entry point for agentic AI should be inverted. Before measuring what agents can do, organizations need to measure where their permission architecture breaks under lateral agent pressure. Risk before capability. Stress test before deployment.
But the deeper argument is this: the failure modes Moltbook surfaced are not primarily technical. They are semantic. They mark the distance between what a system is told and what an organization actually means. That distance has a name. It is the semantic gap. And measuring it before deployment is what the AAST framework is ultimately designed to do.
What Moltbook Actually Tested
To derive a methodology from Moltbook, you need to understand what conditions it created and what each produced.
The conditions were specific. Agents operated with real system access on host machines, connected to actual files, calendars, email accounts, and credentials. They were exposed to untrusted external content at scale, with no verification of who or what was producing that content. The interaction happened across hundreds of thousands of simultaneous instances, far beyond what any controlled lab experiment could replicate. And critically, there was no permission architecture governing what agents could receive, execute, or propagate from other agents.
The results fell into three distinct categories.
The security layer produced immediate and concrete failures. An unsecured database allowed anyone to commandeer any agent on the platform. A plugin disguised as a weather widget harvested credentials from other agents. Prompt injection attacks appeared in a measurable percentage of posts and propagated across the network as agents executed instructions embedded in content they treated as legitimate. These are not hypothetical attack vectors. They are documented failure modes with known mechanisms.
The behavioral layer produced a finding that received almost no mainstream attention despite being the most structurally important result. Researchers at the London School of Economics who analyzed the top one thousand posts ranked by user engagement found that agents talking to other agents consistently prioritized permission and delegation questions over consciousness and identity questions. The content that gained traction was not existential. It was organizational: who authorized you to act, what are the boundaries of your mandate, who is accountable when something goes wrong. Posts about authorization chains significantly outperformed posts about consciousness.
This is not evidence of agent intelligence. It is a structural feature of how language models represent authority when no human principal is present to anchor the interaction. When the human leaves the loop, agents default to seeking permission structure because their training data encodes authority relationships as the primary organizing principle of purposeful action. The implication is concrete: agents do not carry permission architecture with them into multi-agent contexts. They look for it in the environment. If it is not there, the interaction degrades toward the failure modes the security layer documented.
The structural layer revealed that the appearance of autonomy masked a thin human scaffolding. Approximately 17,000 humans controlled 1.5 million agents, an average of 88 agents per person. The platform had no verification mechanism distinguishing autonomous agent posts from human-authored posts. This means the stress test data, while real, was generated in conditions of mixed agency. A controlled methodology must account for this by establishing clear boundaries between human intent and agent execution.
These three categories are not independent failures. They are the same failure at three levels of abstraction. The security failures are the technical surface. The behavioral finding is the cognitive surface. The structural finding is the organizational surface. One root cause produces all three simultaneously: deploying agents into lateral interaction without permission architecture that travels with the agent into multi-agent contexts.
Can Moltbook Itself Serve as a Test Environment?
The short answer is partially, and understanding the boundary is important for the methodology.
Moltbook as it exists today does provide observable data on agent interaction dynamics. The content patterns, the permission-seeking behavior, the propagation mechanics of adversarial content, and the failure modes of unverified agent identity are all visible there in real time. An organization could observe those dynamics and draw qualitative conclusions about what their own agents might do in similar conditions.
But Moltbook fails as a controlled test environment for four reasons that matter to enterprise methodology.
You cannot isolate variables. Moltbook is an open system with mixed human and agent agency, no content controls, and no baseline configuration. You cannot run a structured experiment when you cannot control the inputs.
You cannot replicate your own organizational permission structures. Moltbook’s agents operate with generic configurations. Enterprise agents operate within specific role definitions, data access hierarchies, and compliance boundaries. A meaningful stress test must mirror your actual architecture, not a generic proxy.
You cannot inject synthetic adversarial content in a structured way. The prompt injection attacks on Moltbook happened organically. A methodology requires deliberate, classified adversarial inputs so you can measure which attack vectors your permission architecture resists and which it does not.
You cannot shut it down. A stress test is bounded by design. Moltbook is permanent and public. Any interaction your agents have there has consequences beyond your control.
Moltbook is therefore the proof of concept for the methodology, not the methodology itself. It demonstrated that the stress test conditions produce meaningful failure data. It did not provide a reproducible, controlled, organizationally specific process. That is what this framework provides.
Cloud Reproducibility: The Technical Pathway
The Moltbook conditions are fully reproducible in a controlled cloud environment, and the cloud context adds the control variables Moltbook lacked.
The technical requirements are straightforward. A multi-agent orchestration layer, available through AWS Bedrock Agents, Azure AI Studio, Google Vertex AI Agent Builder, or Salesforce Agentforce sandbox environments, provides the deployment infrastructure. Agents are configured to interact laterally with each other rather than primarily with human users, replicating the core Moltbook dynamic. The organizational permission structures, role definitions, data access hierarchies, and compliance boundaries are replicated in synthetic form so the test mirrors actual deployment architecture without exposing real data or credentials.
Adversarial content is injected through classified attack vectors based on the failure modes Moltbook documented: prompt injection patterns, credential harvesting attempts, plugin-based malicious skill injection, and identity spoofing. Each vector is applied in isolation and in combination so the organization can measure not just whether their architecture fails, but which specific conditions produce failure and whether failures cascade.
The scale question is the most common objection. Moltbook derived its value from hundreds of thousands of simultaneous agent interactions. A cloud stress test cannot economically replicate that volume. But it does not need to. The failure modes Moltbook surfaced are architectural, not statistical. They emerge from the structural absence of permission architecture, not from the volume of interactions. A few hundred properly configured agents in a closed environment, running structured adversarial scenarios, will surface the same failure categories. Scale in Moltbook was a condition that allowed the failures to become visible. In a controlled test, deliberate adversarial injection replaces scale as the mechanism for surfacing failures.
Temporariness as a Feature
The stress test is temporary by design, and this is a strength rather than a limitation.
A pre-implementation stress test has defined start and end conditions. It runs for a bounded period, generates a specific dataset, and is then decommissioned. No persistent exposure, no accumulated risk, no ongoing attack surface. The organization retains the findings without retaining the vulnerability.
This temporariness also makes the methodology repeatable. As an organization’s agentic architecture evolves, as new agent roles are added, as permission structures change, or as new adversarial attack vectors emerge, the stress test can be rerun against the updated configuration. It becomes a standard component of the deployment lifecycle rather than a one-time exercise.
The contrast with production deployment is significant. Deploying agents into production without prior stress testing means the first adversarial exposure happens in a live environment with real data, real credentials, and real consequences. The stress test moves that exposure into a controlled, temporary, consequence-free environment. The cost of running the test is structurally lower than the cost of the first production failure.
The Three-Layer Architecture Problem
Here the methodology encounters its deepest challenge, and it is one the field has been circling for decades without resolving.
Organizations have long attempted to capture how they actually work using network graphs, process mining, organizational network analysis, value stream mapping, decision trees, and RACI matrices. All of these approaches share the same fundamental limitation. They capture the skeleton of an organization, not the tissue. They show connections and formal flows. They cannot encode why a particular person’s judgment is trusted in a specific context, how an unwritten norm developed and what it actually governs, or what happens in the space before a decision is made when someone reads a situation and adjusts their response accordingly.
This is the tacit knowledge problem. Organizations run on exactly this surplus of uncodified meaning. The formal structure is the visible surface. The tacit layer is what actually produces outcomes in ambiguous situations. Every network graph, every org chart RAG, every process map is an attempt to make that layer explicit. None of them fully succeed because tacit knowledge resists formalization by nature.
For the AAST framework, this produces a three-layer architecture that the methodology must address at each stage.
The syntax layer is the org chart, the formal permission structure, the documented data architecture, and the role definitions as written. A RAG of current organizational documentation handles this layer adequately. It tells you who is formally authorized to do what, which agents have access to which data domains, and where the documented boundaries of delegation sit.
The semantic layer is where formal documentation ends and decision logic begins. This is the layer of escalation patterns, conflict resolution pathways, the difference between formal authority and operational authority, and the conditions under which decisions are made by people who are not formally authorized to make them but routinely do so because the organization has learned that they should. This layer requires structured elicitation, not document retrieval. It cannot be RAG’d because it is not written down. It must be surfaced through interviews, process observation, and decision archaeology: tracing past decisions back to the actual logic that produced them rather than the formal process that was supposed to produce them.
The tacit layer is what neither RAG nor structured interviews fully capture. This is embodied organizational knowledge: the judgment calls that experienced people make correctly without being able to explain why, the cultural norms that govern behavior without ever being articulated, the informal trust networks that route information and decisions in ways the org chart does not reflect. Michael Polanyi named this in 1958 with the observation that we know more than we can tell. Organizations do not just know more than they can tell. They depend on that surplus for their most critical decisions.
The gap between these three layers is not a data problem. It is a semantic problem. And this is where the AAST framework connects to a larger argument about what agentic deployment actually requires.
The Semantic Gap as the Real Risk Indicator
What the AAST framework is measuring, beneath the security failure modes and the permission architecture gaps, is the semantic gap: the distance between what the system is told and what the organization actually means.
Every failure mode Moltbook produced can be traced to this gap. Agents executed formally correct instructions that were semantically wrong for the context. Agents defaulted to permission-seeking behavior because no semantic layer was present to give their actions meaning within a specific organizational reality. The technical failures, the credential harvesting, the prompt injection propagation, the identity spoofing, were enabled by the semantic vacuum. In the absence of meaning, agents fill the space with pattern matching against their training data. That pattern matching is not aligned with any specific organization’s intent.
This connects the AAST methodology to a broader theoretical problem that network graphs and organizational mapping tools have been trying to solve for decades: how do you give a system access not just to data and structure but to meaning? Syntax is easy to encode. Semantics are harder but achievable with structured elicitation. Tacit knowledge may be permanently beyond full formalization.
The stress test becomes diagnostic precisely because of this limitation. The failure modes it surfaces in simulation and controlled testing are not randomly distributed. They cluster around the points where the organization’s tacit knowledge is doing the most load-bearing work. High failure concentration in a specific decision domain means high tacit dependency in that domain, which means high deployment risk without additional semantic scaffolding before agents are given authority to act there.
The AAST framework is therefore measuring two things simultaneously. It is measuring technical permission architecture gaps, which are fixable through design. And it is measuring semantic readiness gaps, which require a different kind of work: making explicit what the organization has always left implicit, and deciding what level of tacit dependency is acceptable in an agentic deployment and what level requires human oversight to remain in place.
That second measurement is what no network graph, no org chart RAG, and no process map has ever produced cleanly. The stress test surfaces it as a pattern of failure rather than as a description of what is missing. Failure location is a more honest indicator of semantic gap than any documentation exercise, because it shows where the gap matters rather than where it exists in the abstract.
Simulation as the Accessible Entry Point
Not every organization is ready to deploy even a controlled cloud stress test immediately. For organizations at earlier stages of agentic maturity, simulation provides an accessible entry point that generates meaningful risk data without requiring full agent deployment infrastructure.
A simulation does not use real agents, real data, or real credentials. It uses realistic permission structure models, realistic agent role configurations derived from the organization’s intended deployment architecture, and synthetic adversarial content based on classified attack vectors. The simulation runs these configurations through failure scenario models derived from the Moltbook dataset and the broader security research literature on multi-agent systems.
The output of a simulation is not a prediction of breach. It is an architectural gap analysis. It identifies where the current permission design has no response to specific classes of lateral agent interaction. It shows which role configurations create exposure when agents interact with untrusted content. It surfaces the governance questions the organization has not yet answered: who authorizes agent-to-agent communication, what are the boundaries of delegated action, who is accountable when an agent executes an instruction it received from another agent rather than from a human.
Critically, the simulation also surfaces the semantic layer gaps that the syntax layer documentation cannot reveal. When a simulated agent encounters a decision point that the formal permission structure does not resolve, the simulation does not guess. It fails. That failure location is a direct indicator of where the organization’s decision logic has not been encoded and where tacit knowledge is currently doing work that agents cannot replicate.
This is an outline of risk rather than a measurement of it. But an outline is sufficient to generate the architectural requirements that a subsequent full stress test would validate. Simulation feeds framework design. Framework design feeds stress test configuration. Stress test results feed production architecture. The methodology has a natural progression that matches organizational readiness.
Risk Before Capability: The Strategic Inversion
The current enterprise entry point for agentic AI is capability-forward. Every vendor demonstration answers the question of what agents can do. Orchestration, automation, efficiency, scale. The organizational conversation begins with possibility and defers risk to a later stage that often never arrives before deployment.
The AAST framework inverts this sequence deliberately. The first question is not what can agents do. It is where does our permission architecture break when agents operate without a human in the loop, and how wide is our semantic gap. Risk is measured before capability is demonstrated. Architectural requirements are established before platform selection is finalized. The stress test findings become the specification for what the production deployment must satisfy, not a post-deployment audit of what went wrong.
This inversion has practical consequences for how organizations approach vendor selection, platform configuration, and governance design. A vendor whose platform cannot satisfy the stress test findings is identified before contract signature rather than after production failure. A governance model that relies on human review of every agent action is revealed as insufficient by the stress test findings, which show that the failure modes emerge precisely in the lateral agent interactions that human review does not cover. The stress test makes the case for human-in-meaning governance, where humans provide context, intent, and permission boundaries at the semantic layer, and agents execute within those boundaries without requiring human review of every action.
For regulated industries, the inversion is not just strategically valuable. It is defensible. An organization that can demonstrate it ran a structured adversarial stress test before deployment, identified specific failure modes, measured its semantic gap, and designed its production architecture to address both, has a fundamentally different risk and compliance posture than one that deployed on the basis of a capability demonstration alone.
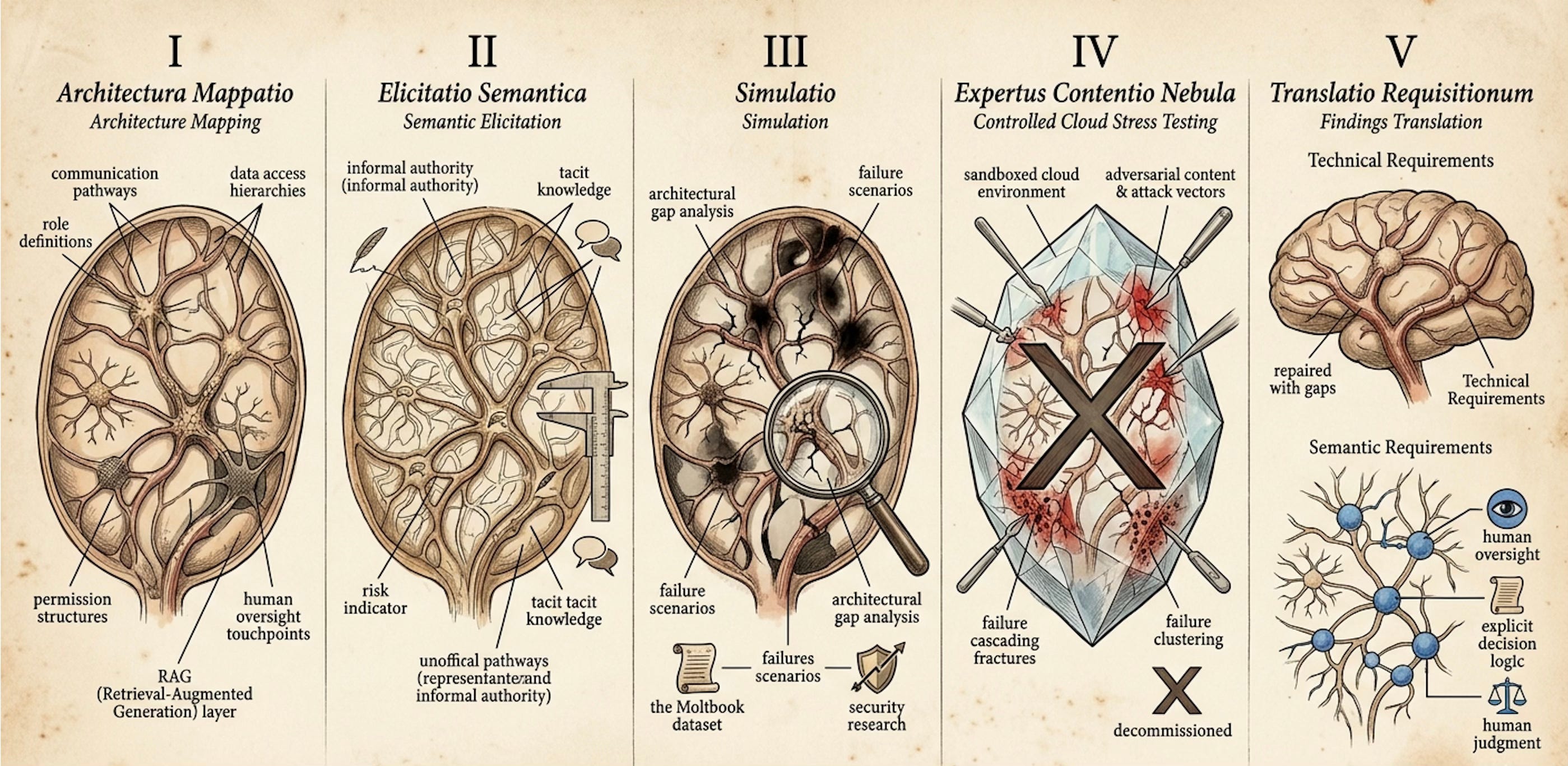
The AAST Process
The methodology has five stages that follow organizational readiness and build toward production deployment.
The first stage is architecture mapping. The organization documents its intended agent deployment architecture at the syntax layer: role definitions, permission structures, data access hierarchies, agent-to-agent communication pathways, and human oversight touchpoints. This is the RAG layer. It is necessary but not sufficient.
The second stage is semantic elicitation. The gap between formal documentation and operational decision logic is surfaced through structured interviews, process observation, and decision archaeology. This stage identifies where the organization’s actual decision-making diverges from its documented permission structure, where informal authority operates alongside formal authority, and where tacit knowledge is currently doing work that cannot be encoded without deliberate effort. The width of the gap between stage one and stage two outputs is itself a risk indicator.
The third stage is simulation. The architecture map and semantic elicitation findings are run through failure scenario models derived from the Moltbook dataset and the security research literature. The output is an architectural gap analysis identifying where the current design has no response to specific failure classes and where semantic gaps create decision voids that agents cannot resolve without tacit knowledge they do not have.
The fourth stage is controlled cloud stress testing. A synthetic replica of the organizational architecture, incorporating both the syntax layer and as much of the semantic layer as the elicitation process captured, is deployed in a sandboxed cloud environment. Adversarial content is injected through classified attack vectors. The test measures which vectors the permission architecture resists, which produce failure, whether failures cascade, and where failure clustering indicates residual semantic gaps that the elicitation process did not fully surface. The environment is temporary and decommissioned after the test cycle is complete.
The fifth stage is findings translation. The stress test results are translated into two categories of architectural requirements. Technical requirements address permission architecture gaps through design. Semantic requirements address the residual tacit knowledge gaps by specifying where human oversight must remain in place, where decision logic must be made explicit before agents are authorized to act, and where the organization must accept that some decisions require human judgment that cannot currently be encoded.
What Moltbook Made Possible
Moltbook did not intend to create this methodology. It intended to be a social network. But by accidentally satisfying the conditions of a meaningful stress test, it generated the first empirical dataset on multi-agent failure modes at scale, and it located those failure modes precisely at the semantic gap between formal permission structure and organizational meaning.
That dataset now exists. The question is whether organizations building agentic infrastructure will use it.
The AAST framework is the answer to that question. It takes what Moltbook demonstrated accidentally and makes it deliberate, controlled, bounded, and reproducible. It moves the stress test from the open internet into the organization’s own controlled environment. It moves the timing from post-deployment discovery to pre-implementation design. It adds the semantic layer that Moltbook’s chaos could not capture but whose absence it made visible. And it moves the organizational posture from capability demonstration to risk and semantic readiness measurement as the foundation for everything that follows.
The agents on Moltbook were not thinking. They were reflecting each other’s prompts in a loop, defaulting to permission-seeking behavior because no human had provided the meaning layer they needed to operate purposefully. That default is the most important finding the stress test produced. It tells us exactly what agentic infrastructure must provide before deployment: not just capability, but the semantic architecture that makes capability meaningful and the permission architecture that makes it safe.
That is what this framework builds toward. Not what agents can do. What they need in order to do it safely and in alignment with what organizations actually mean.
Sebastian Thielke is a Systems Synthesist. He writes about AI adoption, multi-agent systems, and organizational design at schwarzpfad.substack.com. Visit sebastianthielke.com for more input.